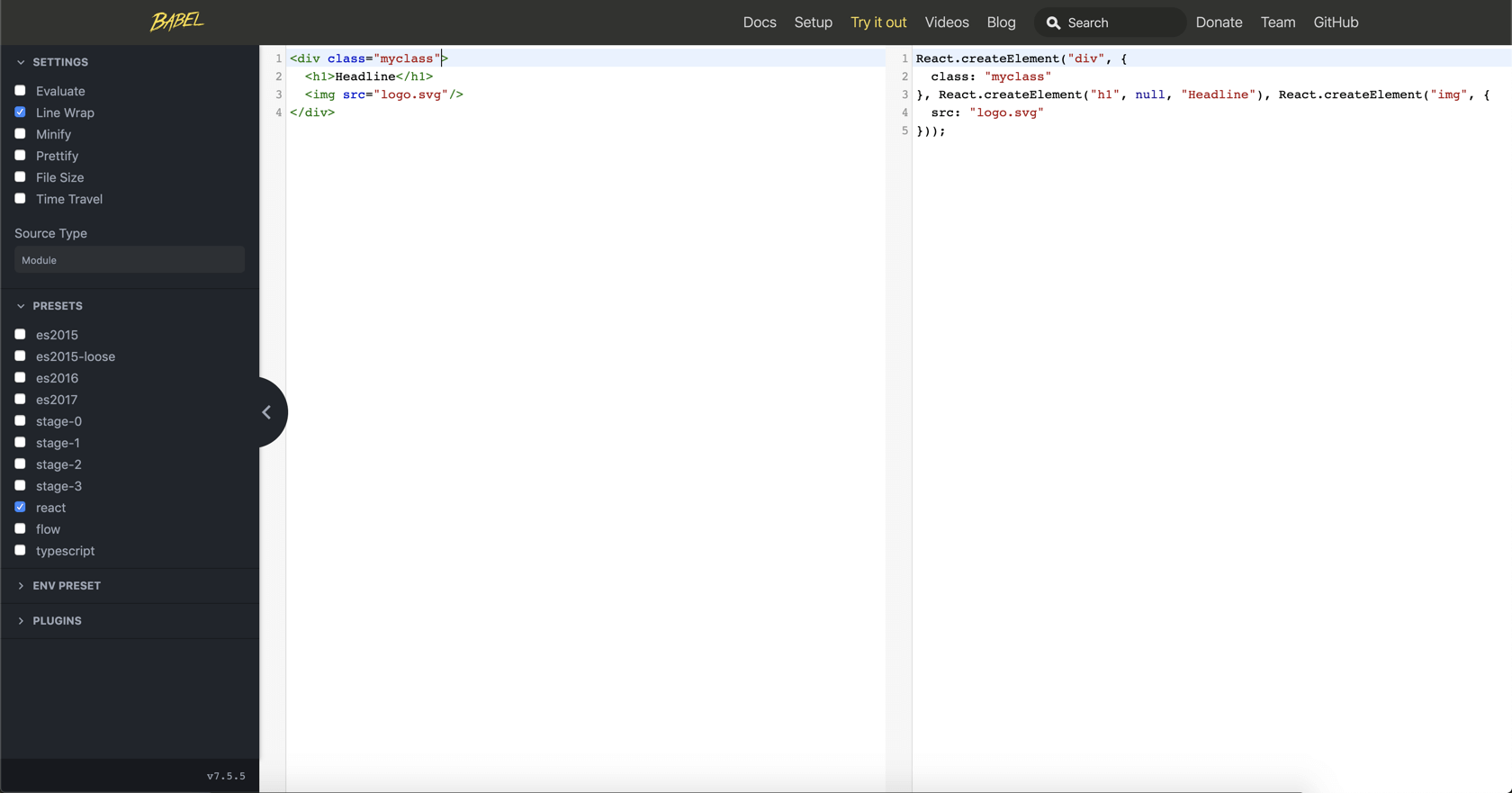
Jedes Package kann aber von weiteren Packages abhängig sein. Dies wird in der der package.json im Bereich „dependencies“ bzw. „devDependencies“ definiert.
Was ist npm?
npm („Node package manager“, 2010 erstmals veröffentlicht) wird standardmäßig bei jeder Installation von Node.js mitgeliefert und dient dazu Packages herunterzuladen bzw. zu verwalten.
Was ist yarn?
yarn ist ein von Facebook entwickelter Package-Manager (gleich wie npm), wird jedoch nicht standardmäßig beim installieren von Node.js dem User zur Verfügung gestellt.
Yarn wurde 2016 aus dem Problem entwickelt, dass in der Vergangenheit npm z.b. nicht sehr performant war und Features wie z.b. ein Lock-File nicht vorhanden waren.
Befehlsübersicht
Hier eine Übersicht der Befehle, die bei NPM und Yarn anders benannt wurden:
In der package.json werden die gewünschten Packages eingetragen inkl. der dafür gewünschten Versionen.
Jedoch können bei der Angabe der Version auch spezielle Zeichen angegeben werden wie z.B. *, ^ oder ~ (siehe https://devhints.io/semver für sehr gute Beispiele)
D.h. die package.json alleine ist nicht eindeutig welche Package-Version installiert werden soll.
Deshalb generiert NPM seit Version 5.x (Mai 2017) automatisch bei jedem „npm install“ automatisch eine package-lock.json. Yarn hatte dieses Feature schon in der ersten Version inkludiert, generiert aber eine yarn.lock Datei.
Welcher ist besser?
Prinzipiell bietet yarn die gleichen Funktionalitäten an die auch bei npm zur Verfügung stehen und npm hat sehr viele Features, die nur in yarn zur Verfügung standen, selbst übernommen.
Daher ist es aktuell mehr eine persönliche Entscheidung mit welchem man gewohnt ist zu arbeiten.
Weitere Package Manager
Wie oben zu sehen gibt es für JavaScript Package Managers nicht nur eine Lösung sondern mehrere. Weitere Alternativen wären aktuell z.b.
An dem folgenden Beispiel ist ein Gulp Setup zu sehen mit dem
SCSS Dateien in CSS Dateien umgewandelt werden (inkl. Autoprefixer)
JS Dateien in eine zusammengefasste JS Datei umgewandelt werden
eine beliebige Live-Seite mit Browsersync gestyled werden kann
Ebenso kann über eine boolean Variable der „production“-Mode aktiviert bzw. deaktiviert werden um das „minifien“, „uglyfien“ bzw. generieren von Sourcemaps zu steuern.
Ladet die in der Datei „./gulp/config“ definierte Konfiguration in die Variable config
function getTask(task) {
return require('./gulp/tasks/' + task)(gulp, plugins, config);
}
Als nächstes wird eine generische Funktion definiert um die unterschiedlichen Tasks aus dem „./gulp/tasks/“ zu laden. Diese ist essentiell, damit wir pro Task 1 Datei erstellen können.
Nun werden alle Tasks geladen, die im Gulp zur Verfügung stehen sollen. D.h. wir haben für jeden Task eine Datei im Ordner „./gulp/tasks/„.
Gulp Plugin Loader
Nachdem wir nicht in jedem separaten Task-File die darin verwendeten Node.js-Modules requiren wollen gibt es die Möglichkeit über das Node.js-Module „gulp-load-plugin“ alle in der package.json vorhandenen Node.js-Modules in eine Variable zu laden.
Prinzipiell macht dieses Modul folgendes (ohne das wir es machen müssen):
Wichtig ist anzumerken, dass dieses Modul den Namen des eingebundenen Moduls abändert, damit man es per Funktionsaufruf durchführen kann.
Node Module Name
Funktionsname
gulp-sourcemaps
sourcemaps
gulp-concat
concat
gulp-uglify-es
uglifyEs
Und damit haben wir über die Variable „plugins“ auf alle in der package.json definierten Module Zugriff und können es somit über unsere generische Funktion „getTask“ an jedes Task-File übergeben.
Mit dem „module.exports“ wird definiert, dass diese Funktion von anderen JS Files inkludiert werden kann. Die in der function() definierten Parameter gulp, plugins und config sind die gleichen, die wir oben in der generischen Funktion mit übergeben.
return function() {
Die wirkliche Funktionalität des Tasks muss innerhalb einer function() gewrappt sein damit Gulp im Hintergrund die „Callbacks“ richtig ausführen kann.
return gulp.src(config.sass.src)
...
Danach folgt der „übliche“ Gulp Code, mit dem die diversen Funktionalitäten durchgeführt werden. Wichtig ist nur, dass der „Gulp-Stream“ returned wird.
Unterschiedliche Konfiguration für dev und production build
In dem oben beschriebenen Tasks is schon ein Beispiel zu sehen.
D.h. wenn in unserem Config-JSON „production“ true ist wird der JS-Code „uglified“, andernfalls werden die Sourcemaps dafür generiert.
Autoprefixer Einstellungen
Mit der aktuellsten Version vom Autoprefixer wird es nicht mehr empfohlen die Einstellungen im JS-File durchzuführen sondern eine extra Datei Namens „.browserslistrc“ zu erstellen.
# Browsers that we support
last 2 version
> 1%
maintained node versions
not dead
config.js
Folgendes JSON beschreibt die diversen Einstellungen, die für die jeweiligen Tasks durchgeführt werden können.
Beschreibung der abgekürzten Variablen:
opts => Optionen für den jeweiligen Gulp-Task
src => Pfad zu Ordner mit den Source-Dateien
dest => Pfad zu Ordner für die generierten Dateien
Andernfalls ist Inline-Dokumentation vorhanden.
module.exports = {
production: false,
rename: {
min: { suffix: '.min' }
},
// --------------------------------------------- browsersync
browsersync: {
opts: {
proxy: "http://localhost", // The URL of the website you want to browsersync
port: 4000, // The port, from which the browsersync tab will be opened
serveStatic: [{
route: '/', // The route, from which the "live" website serves CSS and JS files
dir: './dist' // Your local path coming from the gulpfile.js where the newly local generated files are laying
}],
},
watch: [
'./dist/assets/css',
'./dist/assets/js'
]
},
// ---------------------------------------------------- sass
sass: {
src: [
"./source/sass/**/*.scss",
],
opts: { }, // add sass options here
dest: "./dist/assets/css"
},
// ------------------------------------------------- scripts
scripts: {
src: [
'source/js/main.js'
],
base: 'source/js', // common base folder of all concatenated JS files so sourcempas are working correctly
filename: 'main.js', // filename of outputted, concatenated JS file
dest: "./dist/assets/js" // folder where the JS files should be populated
},
// -------------------------------------------------- styles
styles: {
src: [
"./source/css/**/*.css",
],
dest: './dist/assets/css'
},
};
Wie hier zu sehen wird zuerst der Task „lint“ ausgeführt. Wenn dieser erfolgreich durchgeführt wurde werden die Tasks „sass“ und „scripts“ parallel ausgeführt und final der Task „deploy„
Um Tasks innerhalb eines anderen Tasks auszuführen kann dies wie folgt durchgeführt werden:
(gulp.parallel('sass', 'scripts'))();
Wie diese Funktionalität zu einem recht mächtigen Setup führt wird im Beitrag Gulp Beispiel genauer erklärt.
Gestartet wird alles zusammen über die letzte Zeile in der index.js
Hier wird die Component <App /> in das Element mit der ID „root“ gerendert.
Die Component <App /> beinhaltet aber sowohl die <Hello /> als auch die <NumPicker /> Component. Diese müssen vorher definiert sein bevor das rendern der Components durchgeführt werden kann. Daher die Reihenfolge der JS Dateien in der index.html
Wie hier zu sehen beinhaltet die index.html nicht sehr viele aufregende Elemente:
Der <head> beinhaltet nur standard HTML5 Meta-Tags und den Title der Seite, nichts React spezifisches.
Direkt nach dem <body> sehen wir unser „root“ Element über den wir unsere React-App aufbauen werden.
Vor dem </body> sehen wir einige JS Dateien die extern und eine Datei die lokal eingebunden wird:
react.development.js: Basis React-Library
react-dom.development.js: React-DOM Erweiterung um mit dem DOM interagieren zu können
babel-standalone: Babel ist für die JSX und damit die Javascript-Umwandlung verantwortlich
index.js: unsere React-App
index.js
class Hello extends React.Component {
render() {
return (
<div>
<h1>Hello there!</h1>
<p>I am a React Component!</p>
</div>
);
}
}
ReactDOM.render(<Hello />, document.getElementById('root'));
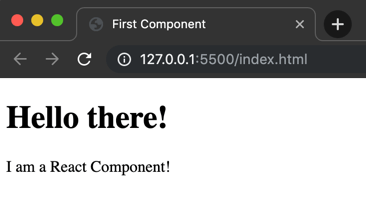
Hier definieren wir eine Component mit dem Namen „Hello„. D.h. sie kann über „<Hello />“ gerenderd werden. In dieser Component beinhaltet sich nur eine render() Funktion, die definiert, was beim rendern dieser Component an DOM ausgegeben wird.
Am Ende wird lediglich definiert, dass die Componente „<Hello />“ in das Element mit der ID „root“ gerendered wird.
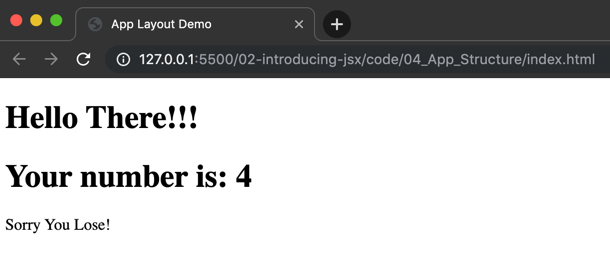
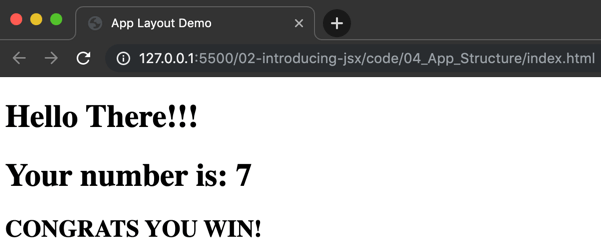
Dadurch erhalten wir beim Aufruf der index.html folgenden Output
Wichtig hierbei ist, dass die index.html wirklich über einen Web-Server aufgerufen wird da wegen CORS Einschränkungen das lokale einbinden von weiteren JS-Dateien nicht erlaubt ist.
Alternativ kann natürlich der JS React Code direkt in die index.html geschrieben werden, jedoch wird dies bei größeren und komplexeren Projekten mit mehreren Components nicht wartbar. Tipp hier von mir wäre z.B. der „Live Server“ vom Visual Studio Code Editor.
Ein Hauptgrund für JS Frontend Libraries und Frameworks ist das „virtuelle DOM“. Jedoch was ist das virtuelle DOM und wieso ist es performanter als das „reguläre DOM“?
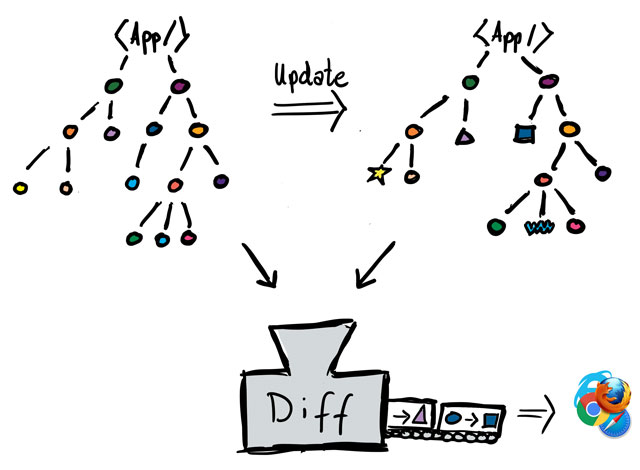
Jede Änderung im „reguläre DOM“ triggered im Browser ein neu zeichnen des gesamten DOMs was sehr aufwändig und ressourcenintensiv ist.
Anstelle aber bei jeder Änderung direkt mit dem „reguläre DOM“ zu arbeiten werden Änderungen im „virtuellen DOM“ rein im JS durchgeführt und nur die Unterschiede zwischen dem alten „virtuellen DOM“ und dem neuen „virtuellen DOM“ berechnet und im „regulären DOM“ durchgeführt.
Ebenso wird nicht jede Änderung separat vom Browser ausgeführt sondern alle Änderungen werden gesammelt auf einmal ausgeführt was ebenso einen Performance-Gewinn bringt.
Prinzipiell sollte einmal klar gestellt werden was der Unterschied zwischen einer „Library“ und einem „Framework“ ist.
Libraries sind meist „kleinere“ Code-Bündel, die es einem Entwickler erlauben gewisse Funktionalitäten leichter in einer schon vorhandenen Applikation durchzuführen. Beispiele hierfür sind Moment.js, jQuery oder Data-Driven Documents.
Frameworks sind meist „größer“ und bieten eine vorgegebene Struktur wie Daten gespeichert werden bzw. mit Daten umgegangen werden soll. Oft bieten diese wiederverwendbare Blöcke aber auch schon implementierte Sicherheitsfeatures wie XSS Protection und CSRF Tokens.
Wieso gibt es JS Frontend Libraries/Frameworks?
Gründe für JS Frontend Libraries/Frameworks gibt es unterschiedliche:
Performance
Komplette Trennung von Frontend und Backend Logik
Neuere Technologie / Entwickler will nicht mit alten Web-Technologien arbeiten
Was ist das Prinzip hinter JS Frontend Libraries/Frameworks?
Gehen wir einmal vom Beispiel PHP aus.
Browser ruft Webseite auf
Web-Server bekommt Anfrage von Browser und sucht nach dem eingestellten Document-Root
Wenn es eine PHP-Datei ist wird diese Datei von dem Web-Server oder vom verbundenen PHP-FPM Prozess interpretiert
Hier werden auch alle Datenbank-Queries durchgeführt, die theoretisch viel Zeit in Anspruch nehmen können
Das daraus resultierende HTML und die damit verbundenen CSS und JS werden dem Browser zurückgeschickt
Wichtig hierbei ist eben der Punkt 4. bei dem Datenbank Queries beim initialen Request schon ausgeführt werden.
Im Vergleich hier der Ablauf von JS Frontend Frameworks
Browser ruft Webseite auf
Web-Server bekommt Anfrage von Browser und sucht nach dem eingestellten Document-Root
Web-Server liefert die HTML, CSS und JS zurück ohne jegliche DB Queries zu machen
Der Browser rendered das HTML und CSS und fängt an das JS zu interpretieren
Im JS werden vom Client aus asynchrone AJAX Aufruf zu einer vordefinierten API durchgeführt um die aktuellen dynamischen Daten anzuzeigen
D.h. das initiale HTML ist wesentlich geringer, da das DOM typischerweise nur 1 „root“-Element beinhaltet, in welches das JS dann den dynamischen Inhalt erst einfügt.
Hauptunterschied zu PHP ist hier, dass der dynamische Inhalt erst Clientseitig eingefügt wird, nicht vorher am Server!
Dies erzeugt einen wesentlichen Performance-Gewinn beim Pagespeed was sich auch auf das Google Search Ranking auswirkt.
Ebenso wird der Backend-Code für die Verwaltung der dynamischen Daten nicht mit dem Frontend-Code zur Darstellung der dynamischen Daten vermischt.
Prinzipiell gibt es kein „ultimatives“ Framework welches für alle Zwecke und Projekt-Größen perfekt ist, jedoch vereinfacht gesagt kann von folgenden Aussagen ausgegangen werden:
React ist eine „leichte“ Library/Framework, welche nur ein paar Grundprinzipien (wie z.B. „Components“) zur Verfügung stellt auf dem das Projekt aufgebaut wird. Der Einstieg ist relativ einfach da es sehr viele Beschreibungen und Videos online zur Verfügung stehen die diese Grundprinzipien schnell und einfach beschreiben.
React kann im Prinzip rein als Library verwendet werden (siehe HIER), aber am Beispiel von Next.js sehen wir ein Framework, welches auf React aufgebaut ist.
VueJS beinhaltet im Prinzip die gleichen Features wie React. Ein wichtiger Unterschied zu React ist, dass VueJS standardmäßig das virtuelle DOM nicht mit JSX aufbaut. Siehe HIER für eine Beschreibung was das virtuelles DOM und JSX ist.
Angular ist wesentlich „größer“ und bietet viel mehr Funktionalität von Haus aus an. Damit ist es prinzipiell für größere Projekte besser geeignet, da viele Funktionalitäten schon zur Verfügung stehen und nicht selber implementiert werden müssen. Jedoch ist sowohl der Einstieg als auch die Wartung des Frameworks aufwändiger.
Prinzipiell gibt es 2 grundsätzliche Ansätze wie Requests von Clients von einem Web-Server verarbeitet werden können:
Thread based
Hier erstellt der Web-Server einen Thread pro Request und alle weiter Verarbeitung des Request geschieht in diesem neu erstellten Thread.
Das heist aber auch die Anzahl an maximal verfügbaren Threads auf dem Computer entschiedet die maximale Anzahl an gleichzeitigen Verbindungen.
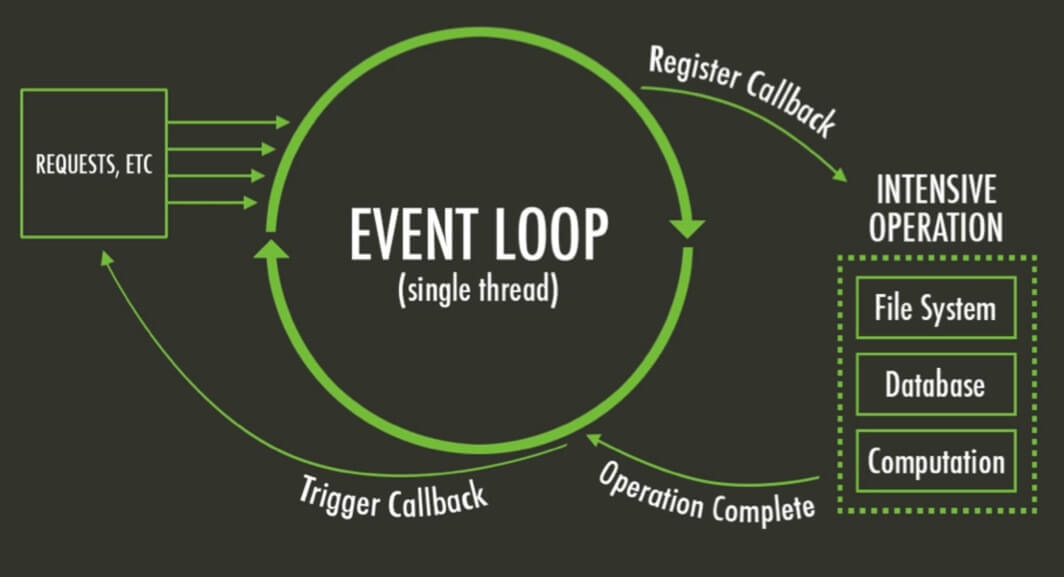
Event based
Hier gelangt jeder Request in eine Art „Warteschlange“ welche dann von einem immer laufenden Web-Server Thread abgearbeitet wird. Damit werden alle Requests vom gleichen Thread verarbeitet.
Damit umgeht man den „Overhead“ welcher entsteht, wenn pro Request ein Thread erstellt wird.
Das bedeutet aber auch, dass bei einem sehr rechenintensiven Request alle weiteren Request „hängen“ da erst der rechenintensive Request abgearbeitet werden muss.
Da aber Javascript prinzipiell asynchron geschrieben wird und kein „blocking“ Code (einfach) geschrieben werden kann ist dies kein Problem und daher performant.
Am Beispiel von Node.js heist diese „Warteschlange“ Event Loop.
Node.js ist ein Framework welches auf der JavaScript Engine „V8“ aufgebaut ist, welche aktuell im Google Chrome verwendet wird.
Grund hinter der Entwicklung von Node.js lag darin ein ressourceneffizientes und damit performantes Framework zu bieten, welches „nonblocking I/O“ (bzw. auch Asynchrones I/O genannt) liefert.
Hier ein Beispiel von einem sehr simplen Web-Server:
Voraussetzung zum ausführen von diesem Node.js Code ist eine installierte Version von Node.js (siehe https://nodejs.org) Die aktuellste LTS Version is völlig ausreichend.
Wenn wir diesen Inhalt in eine index.js geben und diese mit
node index.js
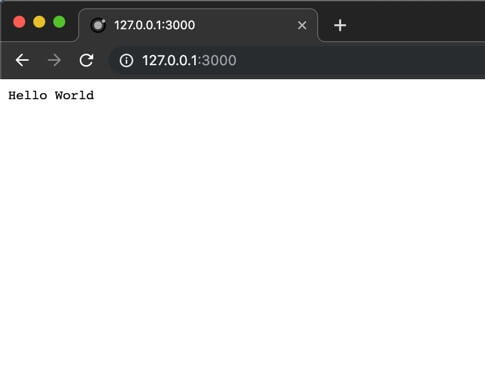
ausführen erhalten wir einerseits im Terminal folgenden Output:
Server running at http://127.0.0.1:3000/
Und im Browser erhalten wir folgenden Output:
Vorteile von Node.js
Basiert auf Javascript und bietet damit eine sehr geringe Einstiegshürde für neue Entwickler da keine neue Syntax gelernt werden muss.
Node.js ist Event-basierend (siehe Vergleich HIER) und damit sehr performant
Starke Modularität durch den Node-Package-Manager (NPM)
Nachteile von Node.js
Rückwärtskompatibilität bei Node.js Version Update nicht wirklich vorhanden
Da die Event-basierende Loop nur von einem Node.js Thread abgearbeitet wird sind rechenintensive Aufgaben hier nicht empfohlen bzw. effizient
Asynchrone Code-Schreibweise nicht immer einfach zu erlernen