Databases offer you possibilities to store information in an efficient way and structure them so you can use the information in any way you need.
Which types of databases are there?
Basically there are 2 main categories of databases:
SQL
The “Structured Query Language” (short SQL) is NO “programming language” in the typical way because it is not Turing complete.
SQL gives you the possibility to describe your data structure in a semantical way.
Example: “Show me all users which are older than 25” can be something like (depending on your SQL structure)
SELECT * FROM users WHERE age > 25
In SQL based database systems the main components are always: databases, tables und columns
You can somewhat compare a SQL database with an Excel sheet.
1 database = 1 excel file 1 table = 1 excel sheet in the file 1 column = 1 column in the sheet
The most common SQL commands are:
SELECT
UPDATE
DELETE
INSERT
CREATE DATABASE
CREATE TABLE
Currently popular SQL database server software are:
MySQL bzw. MariaDB
PostgreSQL
Oracle
Microsoft SQL
Main characteristic of SQL databases are the connections (aka “relations”) which can be created between columns. Thats why SQL databases are also called “relational databases“.
NoSQL
Contrary to SQL based databases NoSQL databases do not have a “fixed” structure how data is being stored.
Dependent on the used NoSQL server software use can store your data in one of the following structures:
Column based (similar to SQL)
Document based
Graph based
Key-Value based
Main advantage of this “freedom” is for example the ease of adjusting the data structure on a live instance due to the fact, that fields in an entry are saved separately and therefore have no influence on already present data in the database.
One example for such a query in a document based database (here MongoDB):
myCursor = db.inventory.find( {} )
WIth that all entries from the collection “inventory” will be returned.
The PHP Composer is a Package-Management Tool similar to NPM or Yarn which you can find in the JavaScript world of NodeJS.
Why do I need Dependency-Management?
There is already so much functional code present out there for e.g. User management inkl. roles, media management, login etc.
Therefore it wouldn’t be bad if you could just “import” these modules into your project and just use them, or not?
But as always in software development there are incompatibilities with specific versions.
And thats why we have composer.
Composer nows through the composer.json and composer.lock which modules need to be installed in which version and which modules are dependent on other modules.
With there 4 lines of PHP you will get a composer.phar in the current directory.
Therefore you can execute composer with the following command:
php composer.phar list
But usually you have composer installed “globally”. This can only be done with admin/sudo privileges:
sudo mv composer.phar /usr/local/bin/composer
Due to the fact that every Linux and MacOS has the path /usr/local/bin/ in the $PATH variable you can now execute composer via:
composer list
Usage
Here are some essential composer commands explained:
composer list
Shows all available composer commands
composer create-project <boilerplate-name>
Creates a composer project with a defined “boilerplate” and creates a composer.json in the current directory.
composer require <modulenmae>
Adds the desired module to the composer.json and executes a composer update.
composer remove <modulenmae>
Removes the desired module from the composer.json and from the file system.
composer update
Updates all currently installed modules with the newest version (dependent on the version string defined in the composer.json) The currently active version is saved in the composer.lock.
composer install
If a composer.lock is present all the modules are installed in the defined version. If no composer.lock is present the given modules in the composer.json are installed in the newest version (according to composer.json) and a composer.lock is created.
composer self-update
Updates the composer version
composer outdated --direct
Shows all modules, which can be updated. The –direct changes the output so only module updates are being displayed, which are defined in the composer.json and not the dependencies behind these modules.
Structure of the composer.json
The simplest composer.json can be created via the command composer init:
Basically only the name of the module devguide/myapp, the author and the dependencies are being displayed here.
require vs. require-dev
As usual in software development there is a separation between the production and the development environment.
To exclude modules from the production environment you have to add these modules in the require-dev area. Modules, which are always required, should be in the require area.
composer install --no-dev
With this command the require-dev modules are not being installed.
Version strings for the composer.json
Name
Short version
Version Range
Exact Version
1.0.2
1.0.2
Version Range
>=1.0 <2.0
>=1.0 <2.0
>=1.0 <1.1 || >=1.2
>=1.0 <1.1 || >=1.2
Hyphenated Version Range
1.0 – 2.0
>=1.0.0 <2.1
1.0.0 – 2.1.0
>=1.0.0 <=2.1.0
Wildcard Version Range
1.0.*
>=1.0 <1.1
Tile Version Range
~1.2
>=1.2 <2.0
~1.2.3
>=1.2.3 <1.3.0
Caret Version Range
^1.2.3
>=1.2.3 <2.0.0
Composer Patches
As always in software development the current “stable” version doesn’t always work 100% as desired.
Before the Composer Module developer publishes a new version of the module you usually have access to patches.
These patch files are normal .patch files, which can be created via GIT.
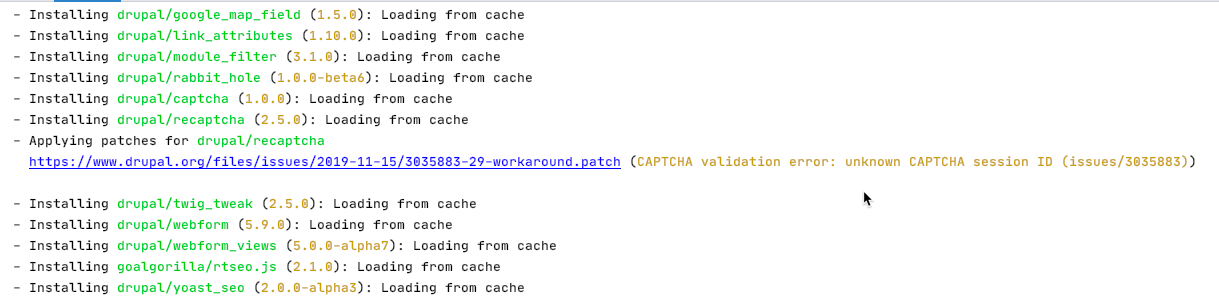
In this example the module drupal/recaptcha will be patched.
If you execute a composer install or a composer update the path should show up in the output:
Problems with patching
In this example the given patch cant be downloaded because the URL is not available. Just check if the given URL is 100% correct.
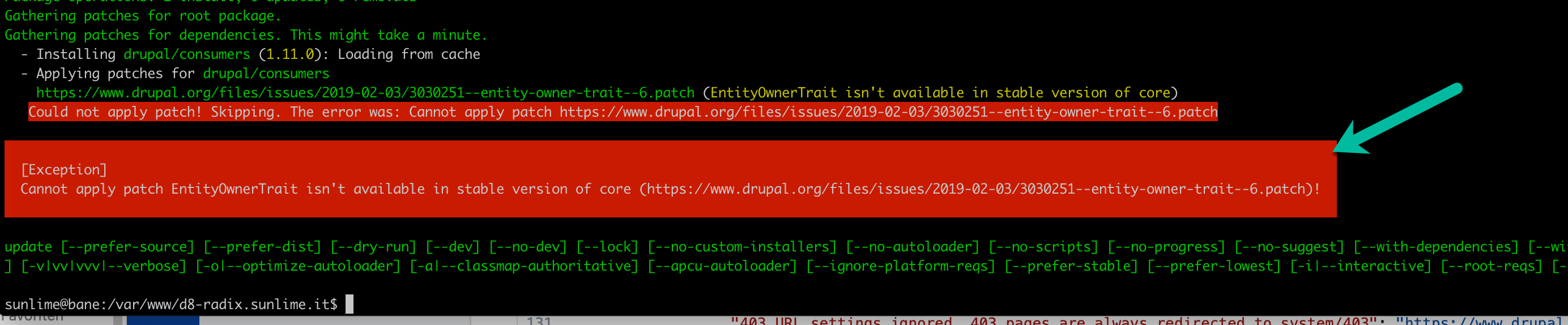
In this example you can see that the patch can’t be applied.
There are several reasons why that can happen, but most of the time this happens, because a newer version of the module has already been installed which already includes the patch.
In that case check the changelog of the module if the given patch has already been applied and a new version has been published. If so just remove the patch from the composer.json
Problems while updating
Permission problems
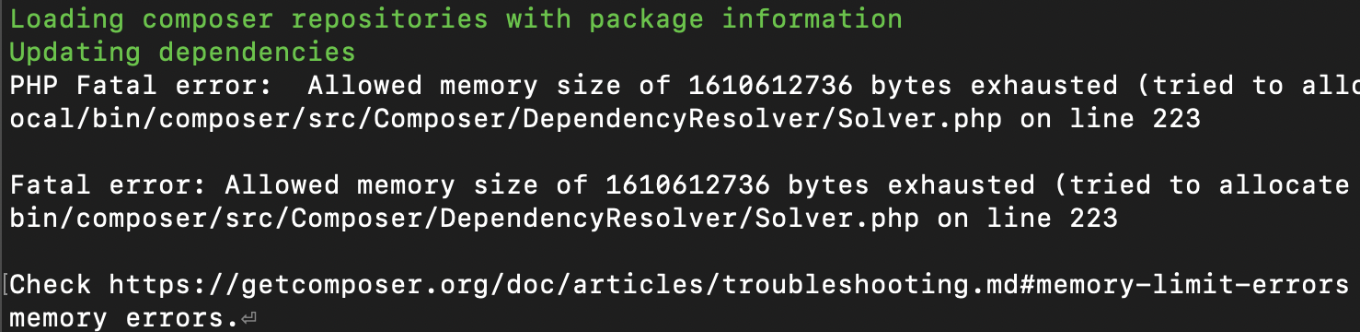
PHP Memory Limit problems
The problem with the Memory Limit can be solved via the php.ini. First check where your php.ini is located:
For Drupal 8 projects you should adjust the following value to at least 3G:
memory_limit = 3G
Permission problems always need to be checked dependent on the current environment.
While the update is running the web-site is NOT accessible and/or will output errors. If possible enable a maintenance mode of your web-site or stop the web server while updating is in progress.
Installed modules don’t match up with composer.json and/or composer.lock
Sometimes it can happen, that composer doesn’t download modules correctly or misses something.
The easiest solution is to delete all generated files/folders and just tell composer to install everything again.
The “System Daemon” (short systemd) is a program, which has many tasks but the main tasks are initialising and manging services like the SSH-Daemon (sshd) or a webserver like NGINX.
Why do I need the systemd?
Just like on your desktop not all programs are running at the same time its the same on a server.
With the systemd you configure which programs should be automatically started when you start/reboot your server. But also you have other commands to manage already running or not running services.
Most important commands
systemctl
Show all loaded services and their status
systemctl start nginx
Start the service nginx
systemctl stop nginx
Stopp the service nginx
systemctl restart nginx
Restart the service nginx completely new (disconnects ALL currently active connections)
systemctl reload nginx
Reload the current configuration for the service nginx neu ein (doesn’t disconnect ANY currently active connections)
systemctl status nginx
Show the current status of the service nginx
systemctl enable nginx
Add the service nginx to the autostart
systemctl disable nginx
Remove the service nginx from the autostart
I don’t have systemd in my linux distribution!
Dependent on your used linux distribution and version you might not have systemdinstalled and configured.
The most common distributions already have migrated to systemd over the last few years. Ubuntu since 2015, Debian since 2014, CentOS since 2014, Arch since 2012 and Fedora since 2011. See HERE for the current list.
Predecessor of the systemd was initd or SysVinit (again dependent on your used distribution)
Where can I find the config for all the already present services in systemd?
The config files for services, which come preinstalled and preconfigured by the distribution, can be found in /lib/systemd/system.
All config files for later installed services can be found in /etc/systemd/system.
Also every user can defined their own services in ~/.config/systemd/user.
The FTP protocol has been developed 1985 to transfer files over the IP protocol. The default FTP port is 21.
Main problem with FTP nowadays is the the fact, that the authentication is NOT ENCRYPTED and can therefore easily be captured if your computer is in the same network as someone with a running Packet-Sniffer like WireShark.
Therefore it is not recommended!
FTP with implicit SSL
FTP with implicit SSL is the next iteration of FTP which should fix the main problem – no encryption. Data transfer usually happens over the Port 990 but before sending the login credentials and further commands a SSL or TLS connection is being established (dependent on the server configuration). The base of the FTP prototoll still stays the same!
Dependent on the server configuration (mainly the used encryption method) you can use this method in a live/production environment.
FTP with explicit TLS
FTP with explicit TLS is more “flexible” than FTP with implicit SSL. First of all the connection is established via the default FTP port 21, but the client has the choice if it wants to just transfer the login data or everything over the TLS connection.
Main problem here is the encryption certificate needed. A valid, signed certificate for this transfer method can only be acquired via a certificate authority (which usually means you have to spend money). You can of course use a self-signed certificate, but on every client connecting to your sever there will be a warning that the used certificate is not signed.
In comparison SFTP doesn’t need any certificate since everything is handled via the SSH protocol.
SFTP
The SSH File Transfer Protocol doesn’t have anything in common with the old FTP protocol since it is based on the SSH protocol and all commands are being sent over one, encrypted connection.
Therefore this is currently the recommended way to transfer data from one PC to another via any network. Also its pretty easy to setup since the SFTP subsystem is present in the default installed SSH-Daemon on a linux system. You just have to activate it.
In comparison for any FTP connection you always have to (no matter if encrypted or not) install and configure a separate FTP server like z.B. VSFTP or ProFTP.
rsync
rsync is a program which is also based on the SSH protocol like SFTP. The main difference is, that only files are being transferred which have really been changed.
“rsync” is a program which enables you to synchronize 2 folders. Basically it’s a better version of “cp”. rsync is built on the SSH protocol to fo example handle authorization and authentication.
Can’t I just use FTP or SFTP?
FTP => NO, SFTP => OK but not as good as rsync
A detailed description of the most common file transfer methods can be found HERE.
Why is rsync better than SFTP if both are based on SSH?
Requirement: Rsync is installed on both sides, client and server.
The main difference here is, that rsync only transfers the changed files from one system to another. Rsync uses a special “delta codec algorithm” and therefore saves a lot of time and traffic.
How do i use rsync?
First you have to check if rsync is installed on both client and server. Via the command “rsync --version” you can check which version you are currently running. Currently it should be (September 2019) at Version 3.
Let’s image the following example:
Your current computer (PC1) has a local folder, which should be synced to another external computer (PC2).
Command
rsync -aP <source> <destination>
So we are logged in to PC1 and have a folder called “wordpress” in our home directory which we want to sync to the external computer PC2 into the directory /var/www/html. For our external computer PC2 we use as an example the address devguide.at and as a user “admin“.
What happens now? Depending on the SSH-Daemon settings of the external PC2 their could a password prompt or nothing happens.
But since we don’t want to enter the users password everytime we want to transfer something we can use the “Public-Key-Auth” so we don’t need to enter anything. See HERE for details.
So now we have configured our “Public-Key-Auth” and can login to the external PC without a password.
ssh admin@devguide.at
Now the following command should run through without any problems.
The difference here is the appended / at the end of the <source> part. It wouldn’t make a difference on the <destination> part if you append a / or not.
But I just want to download something from PC2 to my local PC1!
I just want the files from <source> in <destination> and nothing else!
Per default rsync never deletes anything from <destination> even if they are not present in <source>.
But there are situations when you want to delete any unwanted files from the <destination> and therefore just want to have the state of <source> being present after the transfer is complete.
Whats the difference between a client and an interface?
A client is basically one “physical” computer, which is present inside a network. But one client can have multiple network interfaces to, for example, communicate with multiple different networks.
Can an interface have multiple IP addresses?
Yes! In IPv6 it is “default” to have a “Link Local” and a “Globale” address, but also IPv4 can have multiple IP addresses.
As mentioned in the previous posts we know, what IP addresses are and how an IP network is basically built.
Lets stay with the example from “What is an IP address?” where an IP address is similar to a house address. Therefore we can make the analogy, that a port ist a special entry (door, window or something the like) of a house, which belongs to a special application.
Port numbers can range from 0 to 65535 where some of these are predefined.
System Ports (0 – 1023)
Predefined / standardized ports
User Ports (1024 – 49151)
User can define (if not already occupied by another application) their own ports for their specific application
Dynamic Ports (49152 – 65535)
This area is used primarily by the operating system for dynamically generated port assignments.
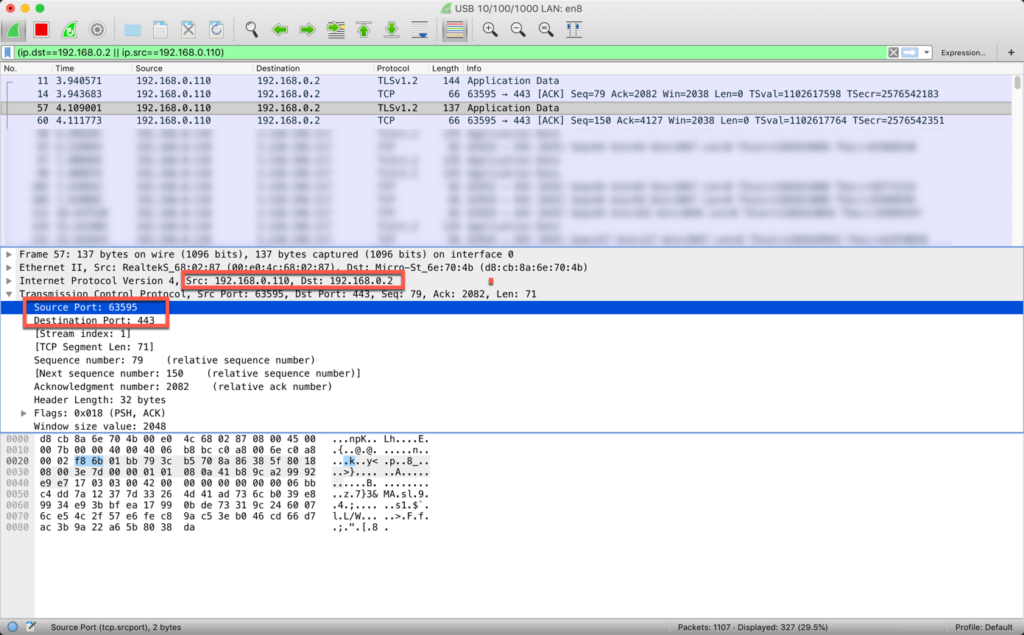
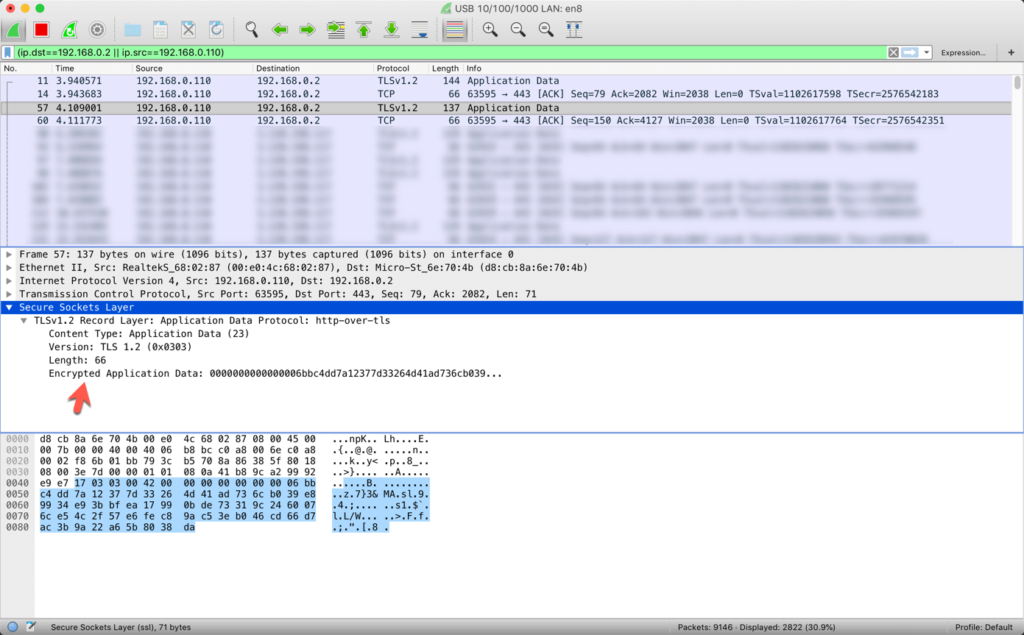
In the following screenshot you can see a section of the application “Wireshark”. In this screenshot you can see an HTTPS request which has been sent from a clients (192.168.0.110) automatically generated port 63595 to my server (192.168.0.2) to the default HTTPS port 443.
Since all my websites are secured via HTTPS we can’t see any more human readable data (like z.b. the HTTP Protokoll) since all the data is being encrypted via TLSv1.2.
To standardize the usage of commonly used applications specific ports have been predefined.
Lets image we only have 1 IPv6 address for our client which for example has been automatically generated by SLAAC (which contains the MAC-Address of the network card).
If this IPv6 address is being used to connect to the internet it would be very easy for tracking tools to identify you as an individual and create a profile.
Thats why random temporary IPv6 addresses are being generated to establish connections to the internet. Since these temporary IPv6 addresses are being deleted and regenerated periodically (depends on the system how often) its pretty hard for tracking tools to create a profile just on an IP address basis.
Secured IPv6 address
ATTENTION: I haven’t verified this information, therefore its just my speculation!
Secured IPv6 addresses keep unique for one interface inside a specific network.
For example you will get the same secured IPv6 address in your home network or you company network to access e.g. a special network share.
Currently this “secured” IPv6 feature is only visible by default on MacOS (June 2019)
Sometimes you do not have the possibility to edit or add files via a GUI.
To create or edit text files you need to use one of the many available terminal text editors. Some popular are:
Vi and Vim
EMACS
Nano
In the following examples I will explain how the “Vim” editor works, since I am used to it.
Is VIM already installed?
The easiest way to check if vi or vim is installed is via one of the following commands: “vim -v” or “vi -v“
If vim or vi is installed you should see something like that:
Create and edit files
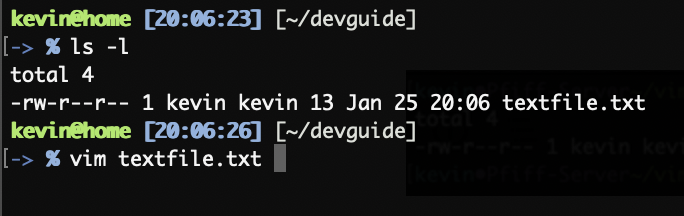
Already present files can be edited via:
vim <Filename>
After that the given files opens in the VIM Editor.
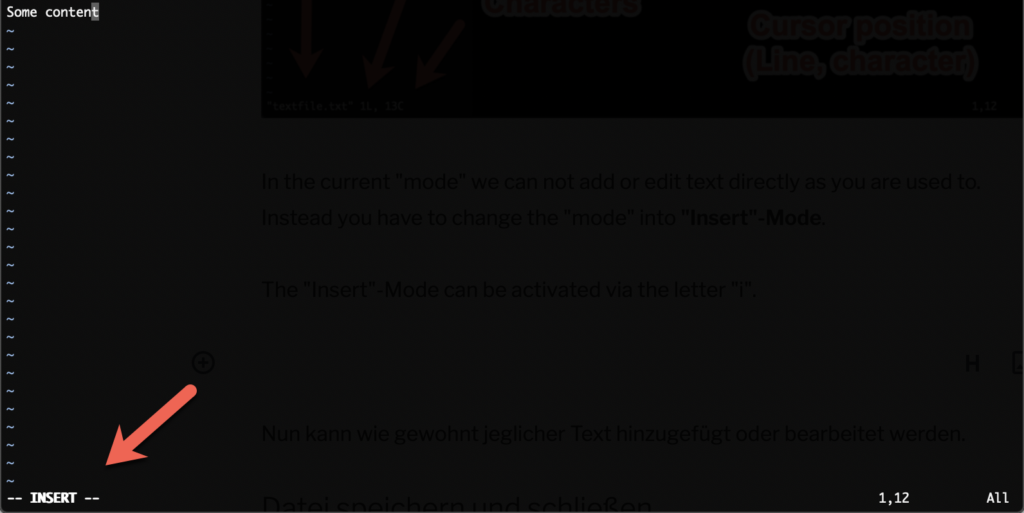
In the current “mode” we can not add or edit text directly as you are used to. Instead you have to change the “mode” into “Insert”-Mode.
The “Insert”-Mode can be activated via the letter “i”.
Now you can add and edit text via the “normal” way you are used to.
Saving and closing files
Now you probably would ask “How do I save the current file?”. There is no bar at the top that says something like “File” => “Save” or something like that.
To execute commands inside VIM we have to get out of the “Insert”-Mode. We can do that via the “ESC” key. After that the text “– INSERT –” at the bottom left of the terminal goes away.
Now we are in the “COMMAND”-Mode and therefore can execute commands
Command
Description
:w
Write
:q
Quit
u
Undo
y
Yank (Copy)
p
Paste
Therefore if we want to save and close the current file we have to input the following command:
:wq
These are the bare basics you need to use vim and therefore manage files in the terminal. A more in depth guide can be found here: https://www.howtoforge.com/vim-basics
Difference between Vi and Vim
“Vi” ca be installed on all POSIX systems, but this version just has the bare “essentiell” functionality built in.
“Vim” (= Vi IMproved) is an extended version of the “default” Vi editor which has built in functions.